In Pictet Technologies, my team relies a lot on decision models. These models allow our business analysts to input Compliance business rules directly into the systems with minimal developer intervention. When I joined the company, we used to use both Drools and Camunda. However, we faced severe memory and performance issues, specifically with Camunda, prompting me to explore alternatives.
For those not familiar with these solutions, both are rules engine providers. And a rules engine is a software system designed to process and execute sets of business rules. These rules provide automated decisions based on a set of inputs. In a nutshell, a rules engine is a very sophisticated if/else interpreter. For more details, I suggest you follow this link.
The first challenge I encountered was with the decision model and notation file (or DMN). By the way, DMN is the “standard” format that both Drools and Camunda implement. While it is relatively easy to understand, it is impossible to load the same file on both vendors. Another point is that most of our cases are simple decision tables. If it were not for the number of rules, it would be simpler to code the business rules in Java directly.
But the most critical issue related to these engines was performance. Our DMN-based services struggled to handle concurrent usage. Even on single requests, the process took longer than our clients were expecting.
Starting the journey Link to heading
Initially, I evaluated alternative solutions, but ultimately, Drools and Camunda were the dominant players in the field when I started these studies. And both were and still are easy to use and integrate with, free to use, and offer tools for maintaining the DMN files.
The next step was using a database, where the rules could be stored and easily accessed through queries. However, this approach quickly resulted in poor performance.
Eventually, I began exploring the possibility of developing my solution, which prompted me to conduct research. That was when I discovered the Trie Tree, a rather basic data structure that arranges words in shared prefixes. Please, follow this link for details on how Trie Tree works. There is also this visualization tool to get acquittance with this data structure.
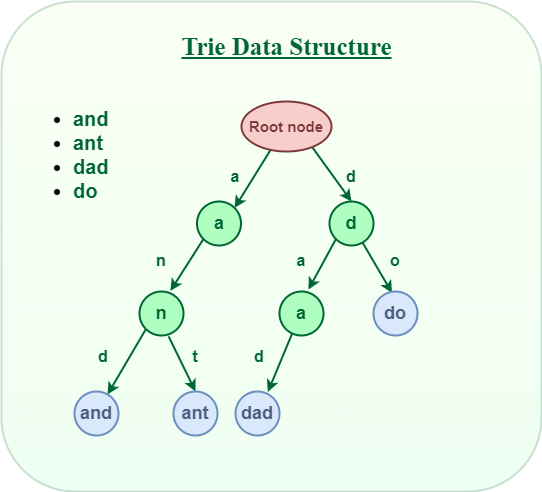
Image reused from GeeksForGeeks
Upon closer examination, I found that treating each input of a rule as a character in a string, Trie Tree is a good solution for a rules engine. The challenge when I started developing it was the “ANY” value, which allows any input value for a given entry. To accommodate this, it was necessary to accurately propagate the children of the ANY node to all siblings, and vice versa, ensuring the correct branch may be traversed.
Another challenge of implementing the Trie Tree was the multiple rules triggering implemented by both vendors. To achieve it using Trie, the leaf node should contain a sorted collection of rule IDs - the sorting mechanism depends on the Hit Policy selected by the developer. In most of our cases, we use the FIRST hit policy, which retrieves the first element of the collection sorted by rule id.
Reviewing the solution Link to heading
The overall performance was exceptional, as demonstrated later. However, memory consumption remained high. After studying other Trie Tree implementations - Radix Tree is an example - I developed an algorithm to eliminate ANY nodes without siblings, as it is always the default branch. This approach reduced some subtrees to just one node.
After further testing, I realized that the number of nodes is significantly smaller if I ordered the inputs appropriately. That is a computationally complex problem, but luckily, there is a simple approach to avoid testing all possible scenarios. One should sort the input entries based on the number of ANY values they have. In one particular service, this technique allowed us to reduce the number of nodes from 30k to 1.5k.
Preparing this article Link to heading
First, I transformed this Trie Tree implementation into an open-source project, which I called Praecepta (Rules in Latin), so anyone can try it out. Then, I added three modules to it, with a decision table based on a real scenario (blurred input/output values). Each module uses a different framework: Praecepta, Camunda 7, and Kogito (the newest Kie solution for the Cloud).
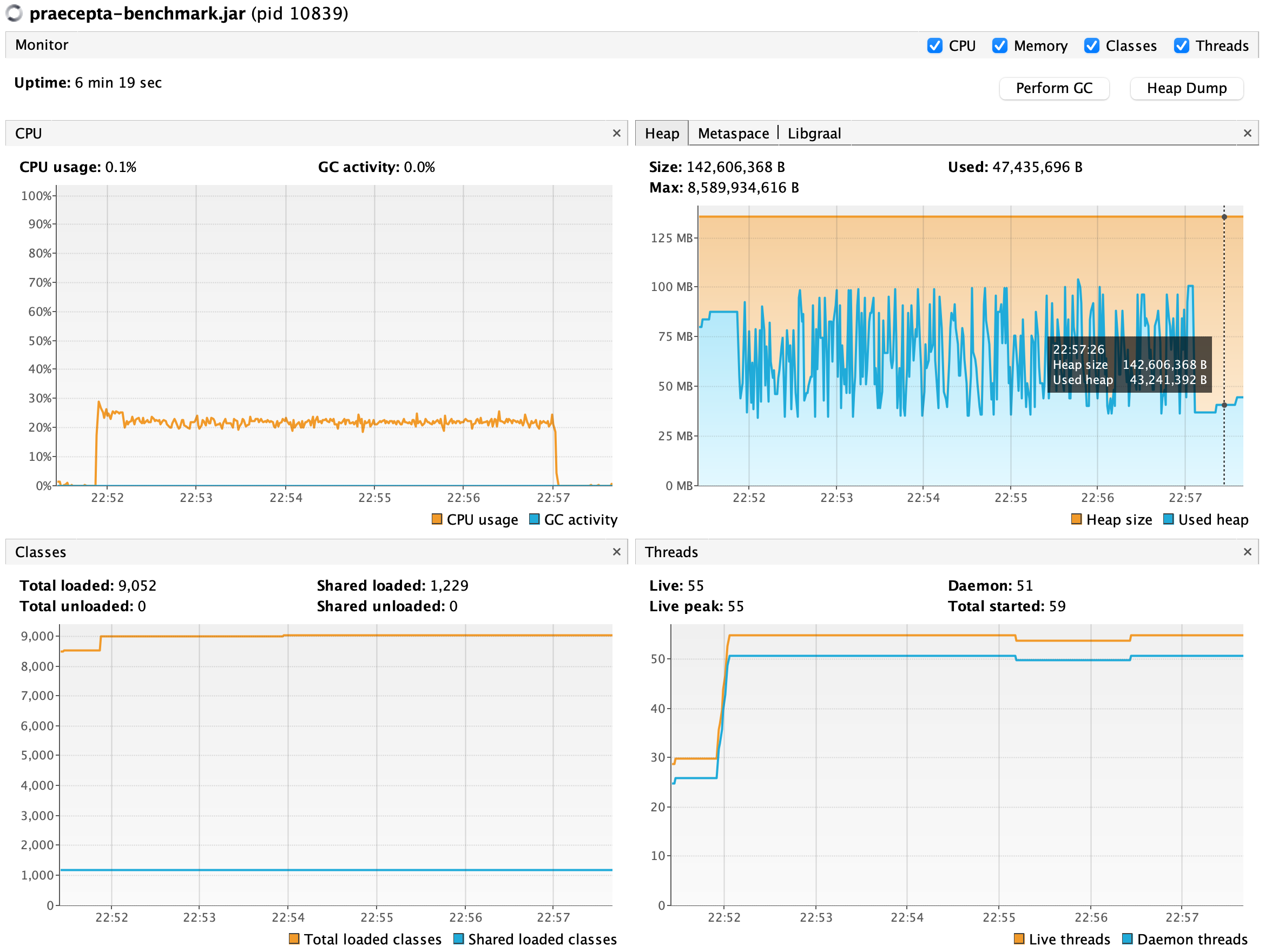
I used SpringBoot 3.0.2, GraalVM 22 (JVM mode), a MacOS 2,6 GHz 6-Core Intel Core i7, running 1000 users for 5 minutes. The idea was to test how memory consumption and CPU usage evolve. Below, I compared the footprint of these three solutions. I collected the total count of requests, throughput, memory consumption, and CPU usage using VisualVM and Gatling.
Beating Kogito and Camunda Link to heading
The numbers do not lie!
| Solution | Requests (total count) | Throughput (mean count/s) | Memory (Peak) | CPU |
|---|---|---|---|---|
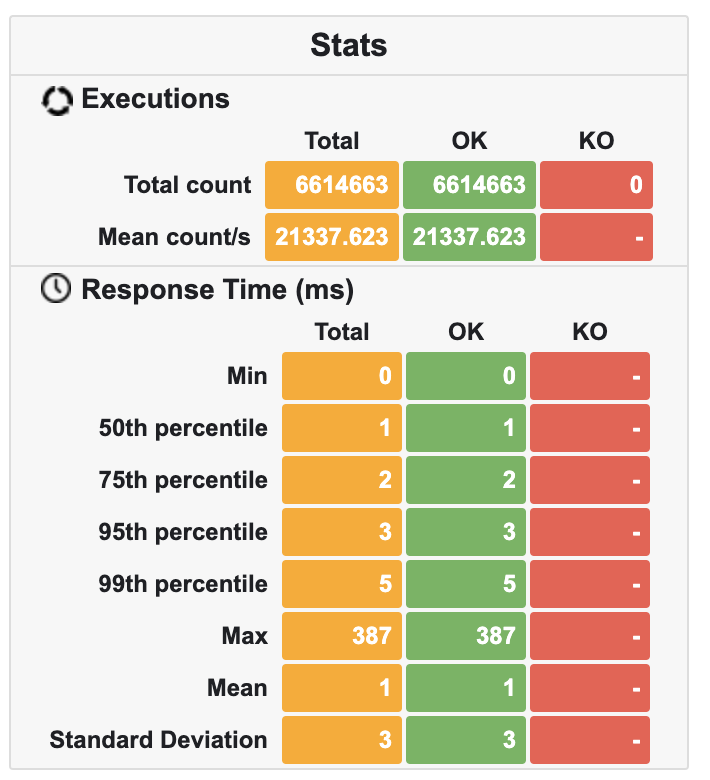
| Praecepta | 6.614.663 | 21.337 | ~100MB | ~25% |
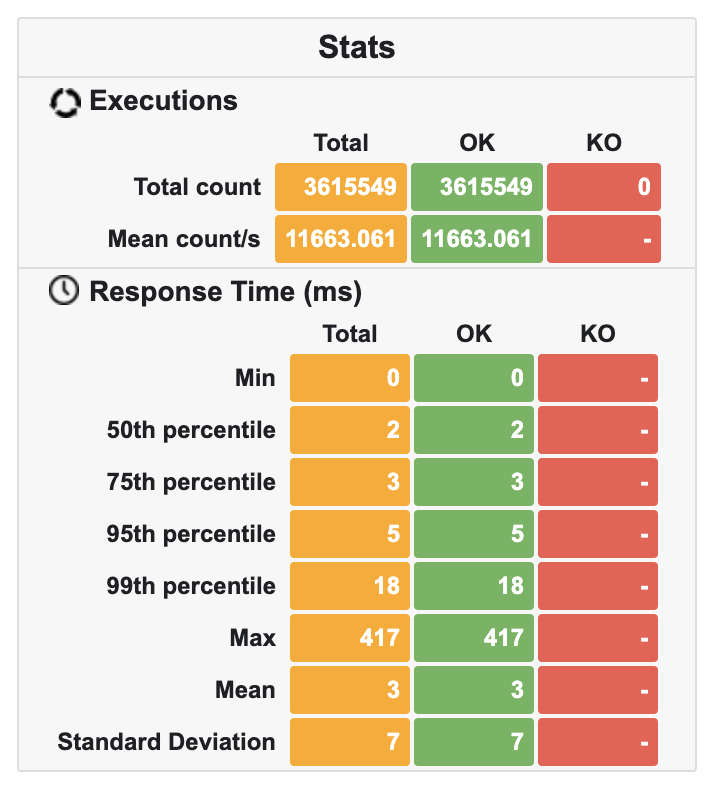
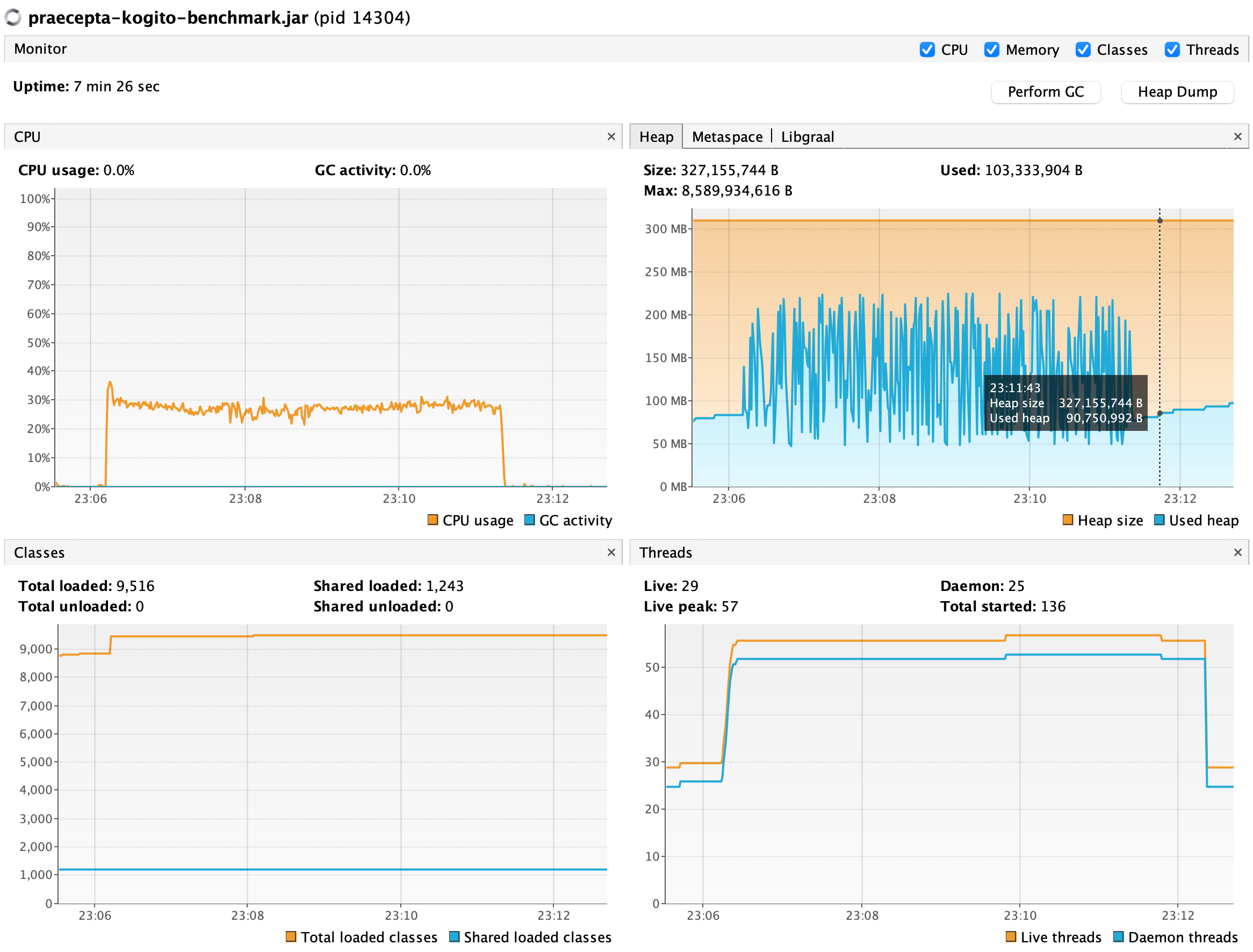
| Kogito | 3.615.549 | 11.663 | ~225MB | ~30% |
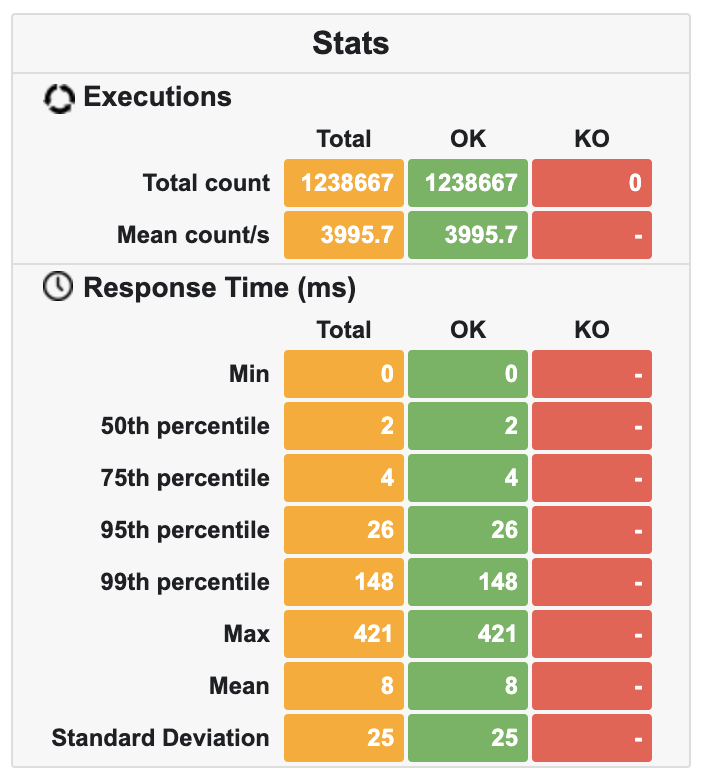
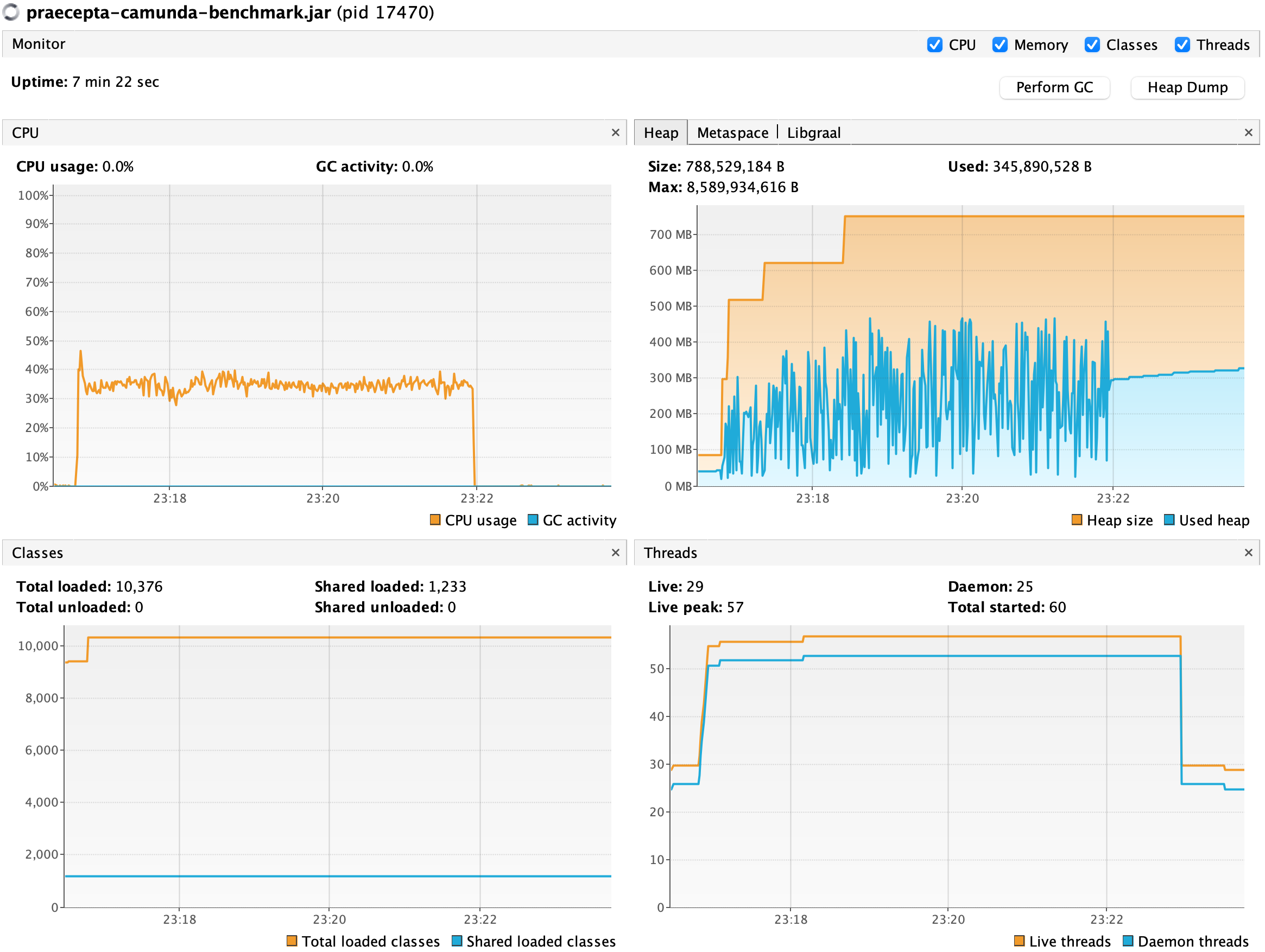
| Camunda 7 | 1.238.667 | 3.995 | ~450MB | ~35% |
Conclusions Link to heading
You can see the results below.
Sadly Camunda 7 did not perform well. It was 3x slower and 2x bigger than Kogito. The last proved acceptable given the numbers, but still, it had twice as much memory as Praecepta. Praecepta, on the other hand, steadily kept memory below 100MB, with low CPU usage and 2x greater throughput, compared to the second place.
The outcome is not that Kogito nor Camunda sucks. It always depends on what we plan and want in our system. If you have a much more complex scenario, Kogito or Camunda may fit better to your needs, but first, you should evaluate other solutions before buying/using one of them.
For our team, a simple data structure had an immensely positive impact. We could provide microservices with a smaller footprint and much higher availability.
For me, It was an excellent opportunity to use my computer science background and learn new things.
Results Link to heading
Praecepta - TrieTree Link to heading
Kogito Link to heading
Camunda Link to heading
See you | Bis geschwënn | Até mais | À bientôt